Full text is a critical point when it comes to mysql. It used to have that feature in MyISAM but that’s not really maintained anymore nor it is advised to use unless you have a very specific use case in which it might make sense. There are 3rd party solution which takes the problem away (Lucene, Sphinx, Solr, ElasticSearch) but all bring extra complexity to your setup which has its own cost. So do you need to give up on fulltext search if you’re using MySQL + InnoDB? No! Definitely not.
Alternatives for full-text search in MySQL
I have an live database with 9000+ products with category, brand and short description which is perfect to test my searches on. I’m going to run the queries many times and use profile information to collect more granular and accurate timing information.
LIKE
Well… It’s not a real alternative but just for a sec see how well it behaves.
|
1 |
SELECT SQL_NO_CACHE b.name, w.name, c.id, c.name FROM ware_ware w LEFT OUTER JOIN ware_brand b on b.id = w.brand_id JOIN ware_category c on c.id = w.category_id WHERE w.name like '%term%' OR b.name like '% term%' OR c.name LIKE '% term%' OR w.short_description LIKE '%term%'; |
Avg execution time: 105 ms
Extra space required: 0
MySQL 5.6 comes with integrated FTS on InnoDB
Innodb now support full text search with the MATCH .. AGAINST commands. Unfortunately if you want good performance you need to materialize your columns into a single column what you create your index on. To do this you can do the following change:
|
1 2 3 4 5 6 7 8 |
alter table ware_ware add column text_gen text, add FULLTEXT fts_idx (text_gen); update ware_ware w LEFT OUTER JOIN ware_brand b on b.id = w.brand_id JOIN ware_category c on c.id = w.category_id SET w.text_gen = concat(w.name, ' ', c.name, ' ', b.name); |
With this you now have a single column with all the text you wanted to index providing one single index you can search against:
|
1 |
select SQL_NO_CACHE w.name, b.name, c.name, match (text_gen) against ('term') as relevance from ware_ware w left outer join ware_brand b on b.id = w.brand_id join ware_category c on c.id = w.category_id where match (text_gen) against ('term') order by relevance desc; |
Avg execution time: 36 ms
Extra space: In my case 38%
it depends heavily on your requirements (what you want to be indexed) but can easily double your table size especially if you want to include relational fields like brand name and category name which make sense, you don’t want one separate FTS index on every column of yours
Disclaimer:
There are solution which could work without materializing but since the primary goal for this test to compare performance I didn’t consider these as viable options.
Can we do better? Yes, we can … implement our own Inverted Index
What is inverted index? An index data structure that maps content such as words or numbers to their location in a file, document or sets of documents. It’s widely used in full text searches. Basically you trade disk space and extra computation on document insertion for speed on the search. Actually InnoDB FTS index is using inverted index as well internally but it’s only in 5.6 and it’s a bit rigid of what and how can you use it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
We create two tables: CREATE TABLE `term` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `term` varchar(255) NOT NULL, PRIMARY KEY (`id`), UNIQUE KEY `term` (`term`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `product_term` ( `id` int(10) unsigned NOT NULL AUTO_INCREMENT, `term_id` int(10) unsigned NOT NULL, `product_id` int(10) unsigned NOT NULL, `num` int(10) unsigned NOT NULL DEFAULT '1', PRIMARY KEY (`id`), UNIQUE KEY `product_term_unique` (`term_id`,`product_id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
With these tables we can rewrite our previous query to something similar:
|
1 2 3 4 5 6 7 |
SELECT SQL_NO_CACHE b.name, w.name, c.id, c.name, sum(num) as score FROM ware_ware w JOIN ware_term_ware tw on tw.ware_id = w.id JOIN ware_term t on t.id = tw.term_id LEFT OUTER JOIN ware_brand b on b.id = w.brand_id LEFT OUTER JOIN ware_category c on c.id = w.category_id WHERE t.term in ('term') GROUP BY w.id ORDER by score desc; |
Avg execution time: 9.9 ms
Extra space: In my case it was 7.6% extra
Comparision
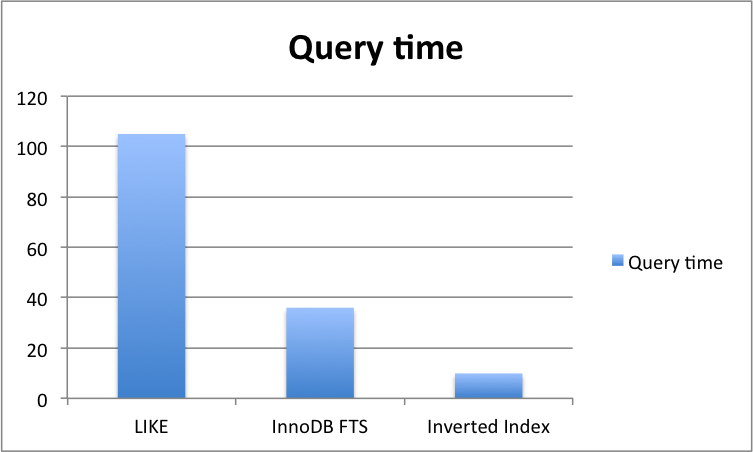
Query time comparison (smaller the better)
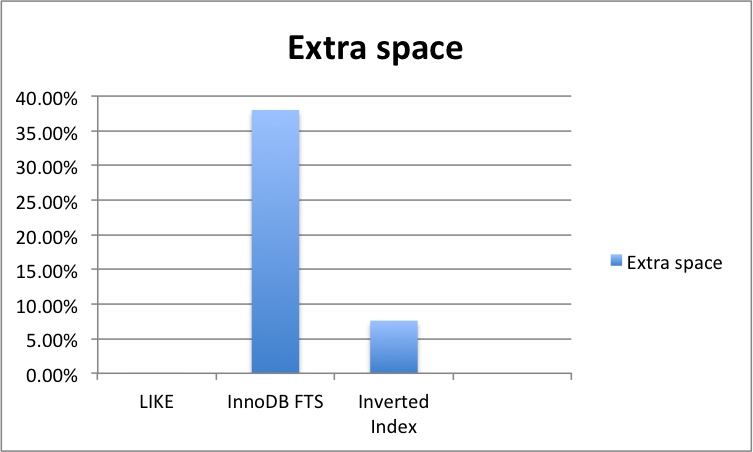
Extra space required by the indexing strategy comparison
(smaller the better)
Advanced features: Ngrams, stemming and tokenising
With this setup you have a flexible solution which you can apply many things on for example stemming and/or tokenisers. Instead of writing the term table with the original text you can do something like this small python code does and write the stemmed words only. (You’re only using that table for searching so storing the stemmed version is totally enough)
|
1 2 3 4 5 6 |
from nltk.stem import SnowballStemmer _stemmer = SnowballStemmer('english’) _words_stemmed = [] for w in text_original.split(‘ ‘): _words_stemmed.append(_stemmer.stem(w)) text_stemmed = ‘ ‘.join(_words_stemmed) |
Also if you want to store n-grams that’s simple too:
|
1 2 3 4 5 6 |
from nltk.util import ngrams sentence = 'this is a foo bar sentences and i want to ngramize it' n = 3 threegrams = ngrams(sentence.split(), n) for g in threegrams: addToTermTable(g) |
Don’t forget to also change your query to search for the stemmed term.
And that’s it. You have a fully functional feature rich full-text search which is performing very well and can be implemented in any database. Getting this idea and take it further you can also do tokenizing by removing accents, replace different characters to whitespace or anything else you can possible think.



Recent comments