Recordsize on data volume
This is the first thing you read when it comes to running MySQL on ZFS. InnoDB is using 16k pages so in theory this makes absolute sense. But as in many situation reality beats theory. We had a competing hypothesis about the optimal recordsize so we setup a test to verify.
Testing different recordsize
System:
- 40 CPU cores
- 128 GB memory
- 5TB FusioIO
The test:
Running sysbench with select_random_points test on a table which is about 5 times larger than the innodb_buffer_pool_size with 12 threads.
Results:
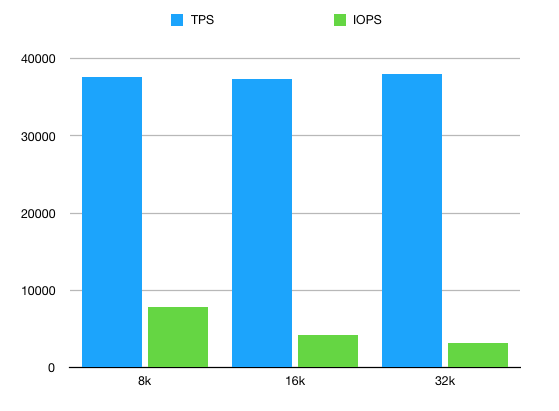
TPS and Read IOPS on different pagesizes
So the 16k and 32k recordsize yields roughly the same TPS for point selects (1.6% improvement with 32k is still good) but it’s doing that with ~26% less IO operations executed on disk. That’s a massive gain especially because databases are tend to be very bound on IOPS even with today’s NVM technology.
The catch:
Of course this doesn’t come for free. Price has to be paid and in this case that price is throughput. Since ZFS is reading 32k on a 16k request there are obviously some extra reads. In our case this was ~28% extra. But as mentioned earlier databases are rarely disk throughput bound. I think any DBA would be happy if they could saturate the throughput of their storage.
Throughput is cheap, IOPS is expensive. Exchanging former for the latter in 1:1 rate is a great deal.
Explanation
InnoDB pages and ZFS records are not guaranteed to be aligned. When InnoDB has to fetch a page from the disk to the buffer pool it issues a request for 16k data which ideally should be a single record but many cases it will manifest in two reads from ZFS.
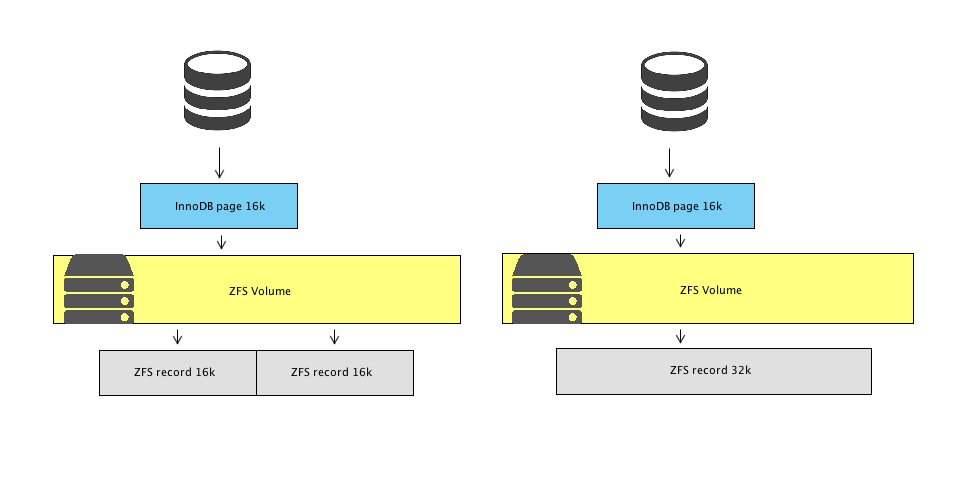
ZFS records misalignment with InnoDB pages with different recordsizes
Conclusion
Test your theories and don’t follow blog posts blindly. Something that works for others not necessarily behaves the same on your infrastructure, under your load pattern, with your data.


Recent comments