Disclaimer: This might sound to be a rant but stay with me and you will see this will be a very good practical advise to speed up your async python code. 😉
Asyncio/Await
Before we go and see how deep the rabbit’s hole is let’s define what asyncio is.
asyncio is a library to write concurrent code using the async/await syntax.
…asyncio is often a perfect fit for IO-bound and high-level structured network code.
https://docs.python.org/3/library/asyncio.html
So asyncio is particularly useful for things like database queries, API requests, IO operation where the CPU wouldn’t do any actual operations but it would stay in WAIT until it gets the requested data from the endpoint.
While it does wait for this IO other operations can be done. This could be either other work within the same application (think about Tornado for example), handling other request or it can progress with the execution and only wait for the data when it becomes necessary.
Await is the keyword indicating that now it’s time to wait for this piece of information.
Forcefully sequentialise
Take a look at the code below. How long do you think it takes to finish?
|
1 2 3 4 5 6 |
async def ioheavyfn(idx): await asyncio.sleep(5) return "bar" for i in range(0, 5): await ioheavyfn(i) |
If you guessed 25 seconds you were right. But where is the benefit of asyncio then? Where is the parallelism? You might ask.
The problem with await in a forloop is that it makes the parallelism (described above) impossible and executes the code essentially sequentially. It does have some benefit if you’re running a highly concurrent web application with Tornado/Twisted or something similar because it can switch to another request processing but there is a much better way to do this.
Asyncio.gather
And here comes asyncio.gather to save the day. The above example is very easy to rewrite like:
|
1 2 |
g = asyncio.gather(*[ioheavyfn(i) for i in range(0, 5)]) await g |
It takes a little over 5 seconds to finish (5.0056 to be precise). So we’re back to properly executing the IO heavy operations “parallel” and we can indicate somewhere in the code that we need this information moving forward.
By this we’re using the coroutines with their full power.
Practical example
Imagine you have some heavy IO operations and some calculations before you can show these to the user. This is very common in web applications (DB query and template parsing), operational tool (gather information from servers and execute), etc.
With this in mind the above example could look something like:
|
1 2 3 4 5 |
queries = asyncio.gather(query1(param), query2(param), query3(param)) t = load_template("sometemplate.html.j2") user_data = parse_json_data(POST['data']) data = await queries t.render(user_data=user_data, data1=data[0], ...) |
Here we can fire the IO heavy database queries at the beginning and while the database is working to fetch those information for us the webserver can parse the jinja template and read the posted JSON data which will be used in the template. We only need to make sure that by the time we call t.render all the database queries have finished.
Benchmark
I’ve created a few mock function to mimic the exact same pattern above with different execution patterns:
- Sync: using full sync “traditional” python
- Async for: using asycio everywhere but doing the queries in a forloop with await
- Async gather: same as above but instead of forloop/await I’m using gather
Each request is executing 10 queries with various response time (between 20 and 500 ms), loads the Jinja template, parses the JSON in HTTP POST data and then renders the HTML. I was running every method 20 times and collected the runtime for each execution.
Results: average runtime
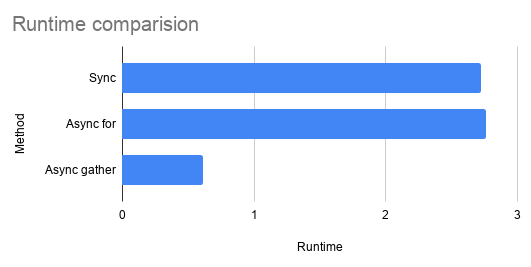
As you can see asyncio.gather outperforms the others as expected. What could be surprising that asyncio with the forloop is actually slower than the traditional sync code. This is because asyncio has certain overhead and it only pays off if the IO operations can be waited parallel which is no possible if you use await in the loop. It’s even better to use sync code at that point.
Results: scalability characteristics
Another important performance metric of a code is how it behaves with increasing amount of queries/inputs/datasources/etc. To simulate this I ran the same benchmark with different number of queries.
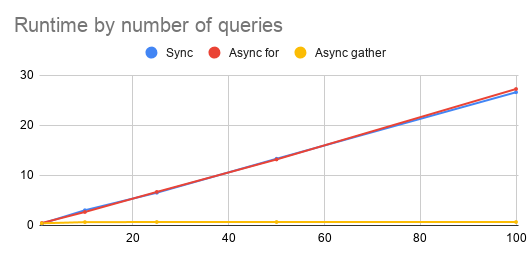
See that the async with await in forloop is performing the same as the sync code would regardless of the number of (async) queries while the proper async implementation has a constant runtime.
The example is relevant because although it is strongly recommended to have small amount of queries in a web request but we were also talking about automation tools where the number of servers are growing constantly and we need to read data from each. In such case we can’t keep the “number of queries” low but we still need a better than linear complexity.
Conclusion
Stop using await in a synchronous forloop!
You’re not achieving anything with that, only making the code more complex for no additional benefit over the simpler, “traditional” sync python code. If you want to use asyncio for performance, scalability benefits, use it properly!



Recent comments