There are a lot of python driver available for MySQL and two stand out the most. The one, traditionally everybody’s choice, sort of industrial standard MySQLdb. It uses a C module to link to MySQL’s client library. Oracle’s mysql-connector on the other hand is pure python so no MySQL libraries and no compilation is necessary. But what is the price for such comfort?
Benchmark
To test that I’ve setup a very simple test case using the world sample database.
Test case single PK lookup
querying random cities by primary key using random from 1 to 8000. Max id in the City table is around 4000 so roughly half of the queries will run into no results and half will produce exactly one row. I did this to see if there is any difference between the two.
I ran 10000 random queries and collected the response times which are resulted in the following graph. On the X axis you can see the primary key value and Y axis shows the response time in ms.
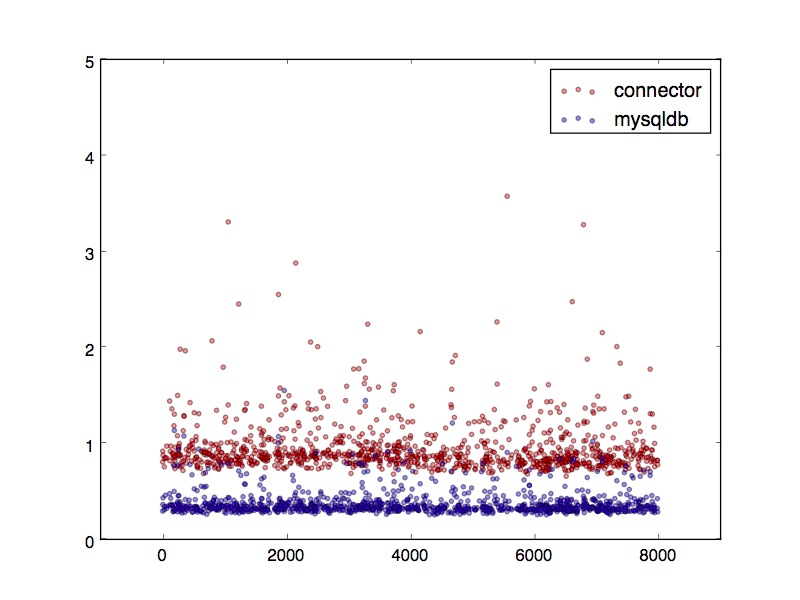
Query times for random PK using MySQLdb and mysql-connector
The difference is quite significant. Most of the query are taking more than two times longer using mysql-connector. It is also much more scattered.
| min | max | avg | stddev | |
| mysql-connector | 0.66 | 154.3 | 1.88 | 11.75 |
| MySQLdb | 0.26 | 1.56 | 0.39 | 0.14 |
Even the minimum time is ~2.5 times bigger using the mysql-connector and the max time is two order of magnitude higher.
Still quick query but larger dataset
I still use primary key lookups but now using id between [lower_bound] and [upper_bound] to produce random number of rows.
X axis it the number of rows returned and Y is the query time. Y maximised at 50 ms to focus on the interesting part.
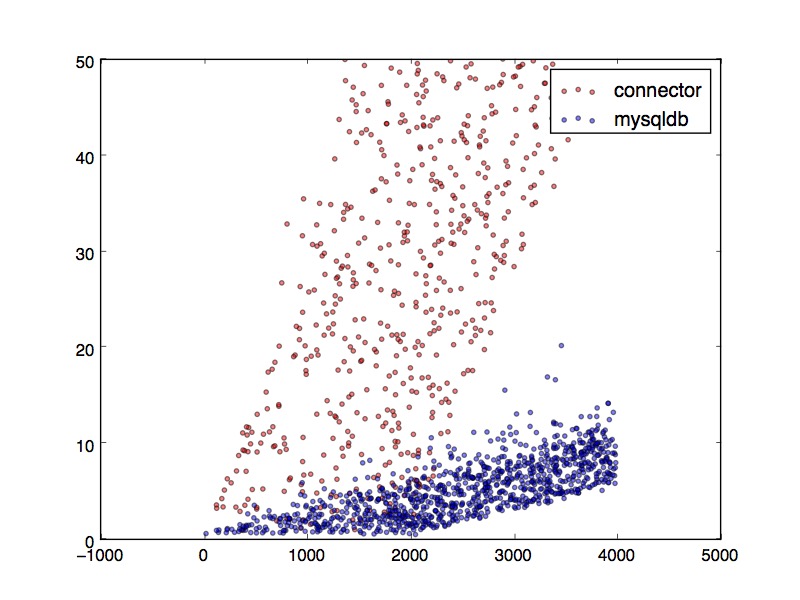
Query times for larger dataset using MySQLdb and mysql-connector
The difference is even more obvious here. With both driver the query time increases roughly linearly but with mysql-connector the growth is much more steep and more scattered again.
| min | max | avg | |
| mysql-connector | 1 | 177.92 | 48.44 |
| MySQLdb | 0.57 | 20.25 | 5.33 |
Since we’re having a linear growth here standard deviation doesn’t make too much sense to look at.
Where does the difference come from?
Using cProfile we can check where each version spends the most time. Now running the queries for 100 times.
|
1 |
$ python -m cProfile -s cumulative mysql_driver_benchmark.py |
cProfile output for mysql-connector
|
1 2 3 4 5 6 7 8 9 10 11 12 |
ncalls tottime percall cumtime percall filename:lineno(function) 1 0.015 0.015 7.617 7.617 mysql_driver_benchmark.py:1(<module>) 1 0.000 0.000 6.747 6.747 mysql_driver_benchmark.py:39(main) 1 0.013 0.013 6.297 6.297 mysql_driver_benchmark.py:26(benchmark) 100 0.078 0.001 6.283 0.063 mysql_driver_benchmark.py:19(query) 100 0.169 0.002 6.040 0.060 cursor.py:822(fetchall) 160570 1.351 0.000 3.152 0.000 conversion.py:363(row_to_python) 100 0.001 0.000 2.689 0.027 connection.py:655(get_rows) 100 0.376 0.004 2.688 0.027 protocol.py:292(read_text_result) 161474 0.774 0.000 1.611 0.000 network.py:219(recv_plain) 481710 0.548 0.000 1.498 0.000 conversion.py:537(_STRING_to_python) 482211 0.290 0.000 0.818 0.000 {method 'decode' of 'bytearray' objects} |
cProfile output for MySQLdb
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
ncalls tottime percall cumtime percall filename:lineno(function) 1 0.004 0.004 0.930 0.930 mysql_driver_benchmark.py:1(<module>) 1 0.000 0.000 0.635 0.635 mysql_driver_benchmark.py:39(main) 1 0.008 0.008 0.435 0.435 mysql_driver_benchmark.py:26(benchmark) 100 0.000 0.000 0.425 0.004 mysql_driver_benchmark.py:19(query) 100 0.001 0.000 0.424 0.004 cursors.py:164(execute) 100 0.000 0.000 0.421 0.004 cursors.py:353(_query) 100 0.001 0.000 0.241 0.002 cursors.py:315(_do_query) 100 0.001 0.000 0.180 0.002 cursors.py:358(_post_get_result) 100 0.000 0.000 0.180 0.002 cursors.py:324(_fetch_row) 100 0.180 0.002 0.180 0.002 {built-in method fetch_row} 100 0.001 0.000 0.173 0.002 cursors.py:142(_do_get_result) 100 0.000 0.000 0.171 0.002 cursors.py:351(_get_result) |
The difference is quite obvious. Now python is doing the heavy lifting parsing and interpreting the data received from the socket while MySQLdb offloads that to the C library. This makes large dataset providing queries even less efficient and the difference is growing with the number of returned rows.
Slow(er) queries
Running SELECT sleep(0.1) queries 100 times results in the following stats. Values are in milliseconds.
| confidence interval | ||||||
| min | max | avg | stddev | low | high | |
| mysql-connector | 101,11 | 106,72 | 102,29 | 0,73 | 100,86 | 103,72 |
| MySQLdb | 100,33 | 104,73 | 101,46 | 0,65 | 100,19 | 102,73 |
There is a slight difference between the averages but as the confidence interval shows there’s no statistically significant difference so we can treat the two as equals.
Conclusion
If you’re having a lot of primary key lookups or other type of quick point queries this difference can be quite significant and probably worth the extra effort to maintain those C binding.
If you query for larger dataset having an efficient way to parse is essential and while querying couple of thousand rows frequently might not be a common task to do the question boils down to if you can afford 20-30 ms extra time in such cases.
However if your queries are not in the millisecond range you probably won’t notice a thing as the overhead gets diminished with longer query runs and becomes insignificant around and above ~100 ms. In this case tune your queries first!


Recent comments