Multi-variant: 3% vs 5% vs 7%
Payoff
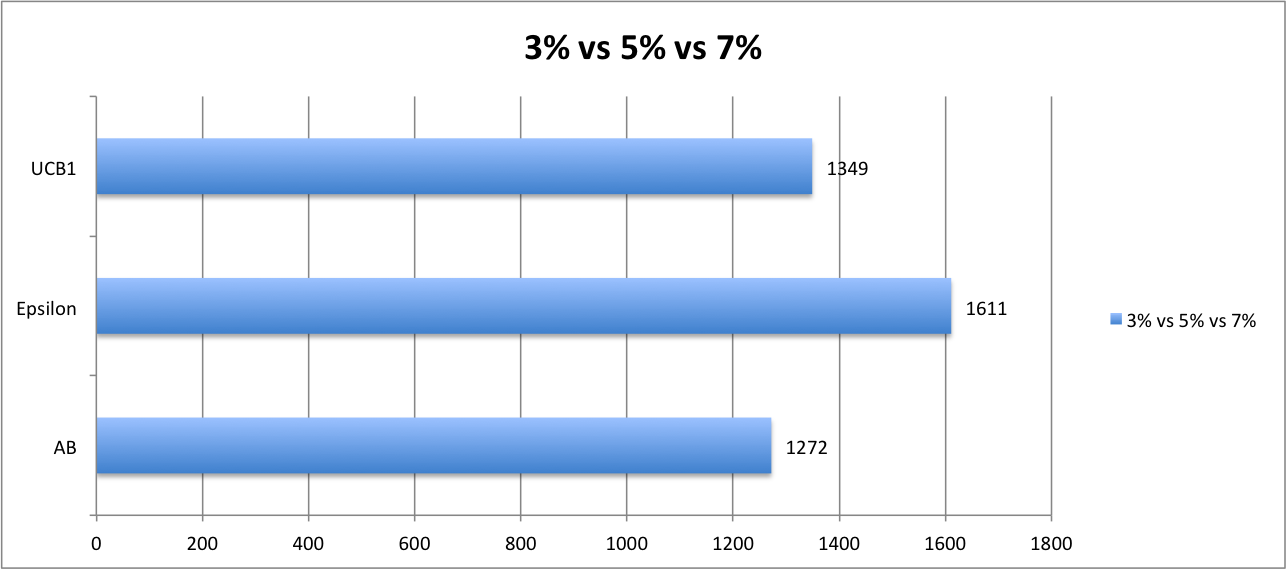
Payoff from variation 3% vs 5% vs 7%
You can probably see a pattern here already. The Epsilon greedy comes out winning in terms of rewards again followed by UCB1 and AB test with a bigger difference now (16% and 21% respectively).
Certainty
The difference is big enough between the variations to reach confidence quite quickly. UCB1 is the fastest followed by Epsilon greedy and AB.
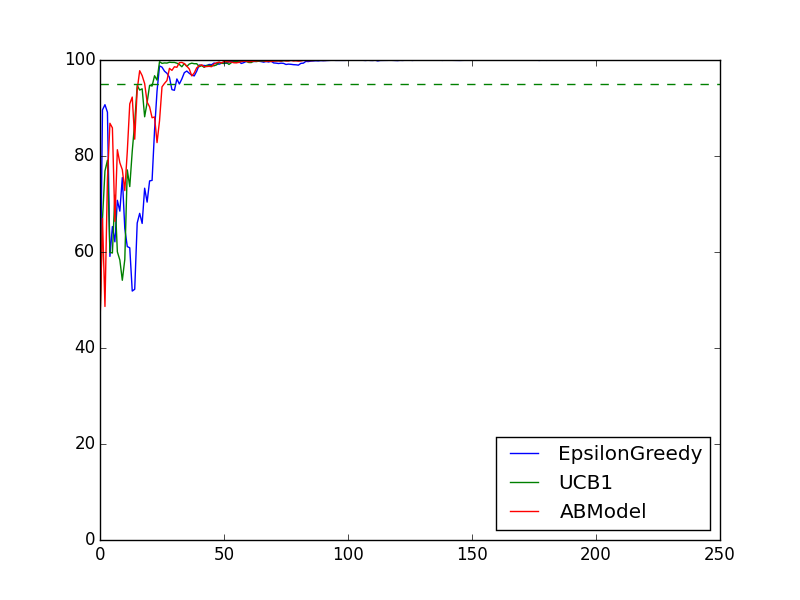
Confidence for 3% vs 5% vs 7%
Run behaviour
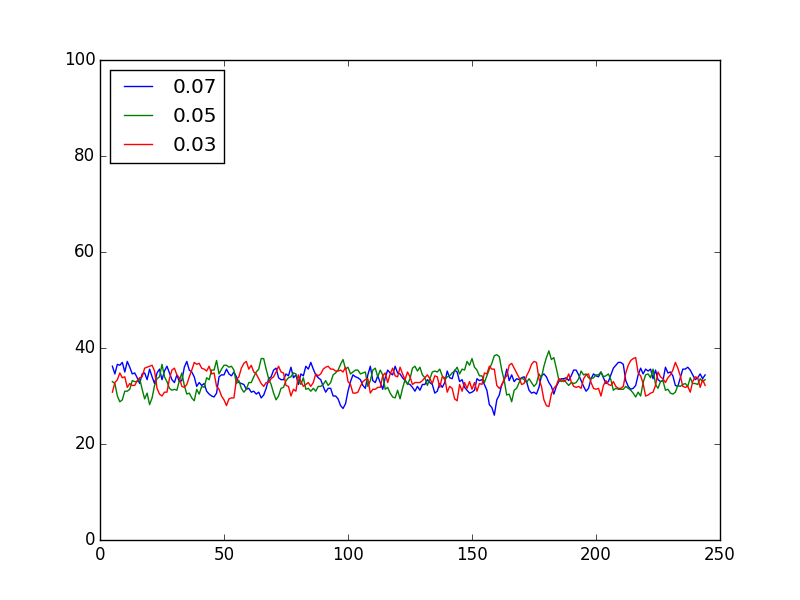
Variations display in AB model
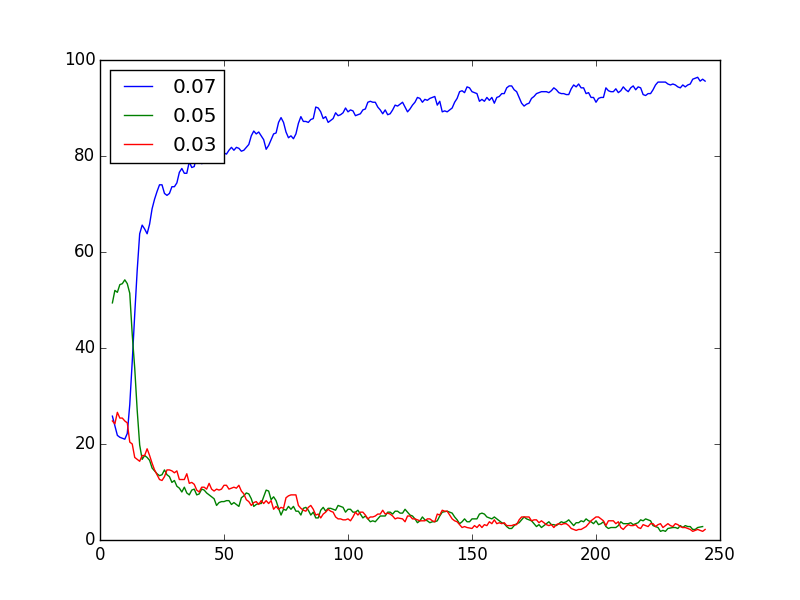
Variations display in Epsilon greedy model
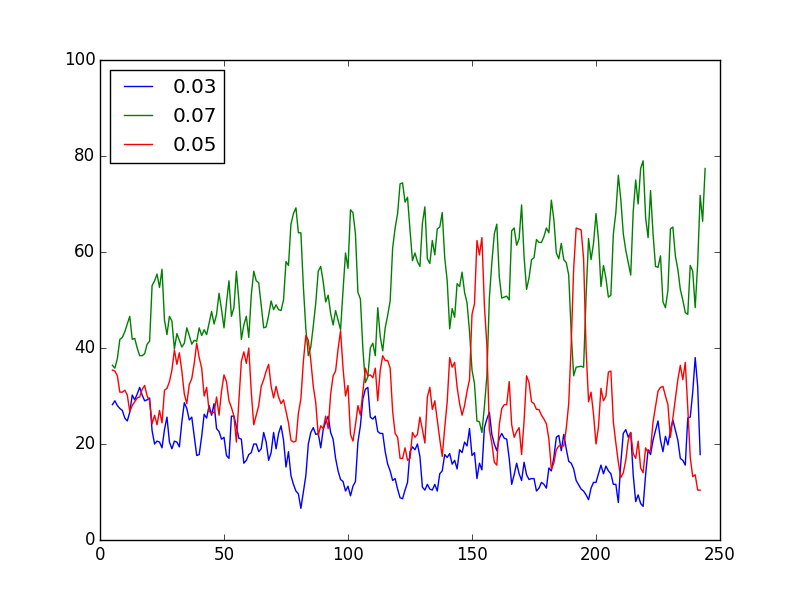
Variations display in UCB1 model
No surprise there. What’s worth to mention is the Epsilon greedy ability to come back from the bad start much quicker than it was in the previous example mostly because the difference is much bigger.
The UCB1 is mostly serving the best performing version probing the second time to time and running the worse on low frequency.
Stopping when confidence level reached
Reaching confidence quite fast again we can check what would have happened if we had stopped when reached 95%.
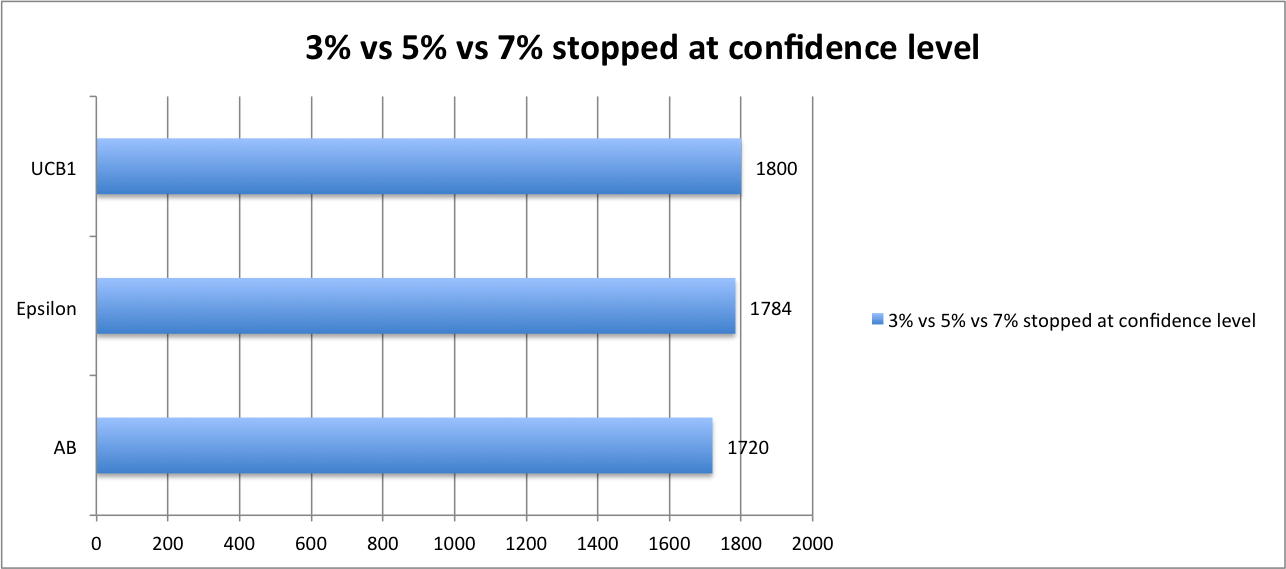
Payoff from variation 3% vs 5% vs 7% if stopped at confidence level
In this case UCB1 comes out first because it’s ability to quickly reach the point when we can switch to full exploit. It’s providing 4.5% higher reward than AB and ~1% more than Epsilon.



Recent comments